Barcelona, September 1st and 2nd, 2022. Universitat Politècnica de Catalunya, Sala d’Actes, Edifici Vèrtex


Our colleague Mateo Valero celebrates his 70th Anniversary!!
We are very happy to share this event with Mateo!! A large number of representatives from our research area, Computer Architecture, will be participating on the workshop.
This website summarizes the event, with the Program details, and will also collect photos, video recordings and slides of the presentations.
Workshop Program
Thursday, September 1st, 2022
8:15 - 8:45 Registration
8:50 - 9:00 Opening & Introduction

9:00 - 10:30 Session 1 (Chairperson: Walid Najjar - UCR, slide)
Yale Patt (Univ. of Texas at Austin)   |
The Microprocessor now that Dennard Scaling is gone and Moore’s Law almost gone (slides, recording)  |
|---|
Details
Yale Patt is a teacher at The University of Texas at Austin where he continues to enjoy teaching, research, and consulting 60 years after beginning his journey into computer technology. Teaching includes the freshman course where he has developed the CORRECT way to introduce serious students to computing, culminating in his textbook (now in its 3rd edition) with his co-author, Professor Sanjay Jeram Patel of UIUC: Intro to Computing Systems, from bits and gates to C, C++ and beyond, McGraw-Hill, 2019. It also includs his senior course in Computer Architecture and his textbook in progress. He has earned the appropriate degrees from reputable universities and has received more than enough awards for his research and teaching. For those who want it, more detail on his home page: www.ece.utexas.edu/~patt. |
Building on the white paper that Charles Leiserson and his colleagues at MIT wrote (There’s plenty of room at the top), I want to address its impact on continuing to enjoy higher and higher performance microprocessors now that Dennard scaling is gone and Moore’s Law will soon be gone. Of course I agree with Charles that the free lunch is over and we must exploit better the higher layers of my transformation hierarchy. In fact, Charles and I discussed the matter more than once before his white paper. Two things are relevant: (1) There is STILL plenty of room at the bottom, and (2) We must augment what we expect from the programming model, the ISA, the compiler, and the microarchitecture to make it happen. I will comment on some of the above. |
Ronny Ronen (Technion - Israel Institute of Technology)  |
Memristive Based Processing in memory - The potential and the challenges (slides, recording)  |
|---|
Details
Ronny Ronen received the B.Sc. and M.Sc. degrees in computer science from the Technion, Haifa, Israel, in 1978 and 1979, respectively. He is a Senior Researcher with the Andrew and Erna Viterbi Faculty of Electrical & Computer Engineering at the Technion. Ronny was with Intel Corporation from 1980 to 2017 in various technical and managerial positions. In his last role, he led the Intel Collaborative Research Institute for Computational Intelligence. Before that, Ronny was the Director of microarchitecture research and a Senior Staff Computer Architect in the Intel Haifa Development Center until 2011. He led the development of several system software products and tools, including the Intel Pentium processor performance simulator and several compiler efforts. In these roles, he led/was involved in the initial definition and pathfinding of major leading-edge Intel processors. Ronny is an IEEE Fellow (since 2008), he co-authored over 35 papers and is a co-inventor of over 80 issued US patents. While at Intel, Ronny was appointed as an Intel Senior Principal engineer (1999) and was awarded three times with the Intel Achievement Award (IAA) – Intel highest technical award. |
Data Transfer between memory and CPU in a conventional von Neumann architecture is the primary performance and energy bottleneck in modern computing systems. To reduce this overhead, we have developed a new computer architecture that enables true in-memory processing based on a unit that can both store and process data using the same cells. This unit, called a memristive memory processing unit (mMPU), substantially reduces the necessity of moving data in computing systems. Emerging memory technologies, namely memristive devices, are the enablers of the mMPU. While memristors are usually used as memory, these novel devices can also perform logical operations using a technique we have invented called Memristor Aided Logic (MAGIC). Different sequences of basic MAGIC operations (e.g., NOR) can be used to execute any desired function within the memristive memory. Furthermore, the mMPU naturally performs massively parallel operations and thus it is an excellent SIMD (Single Instruction Multiple Data) engine. The elimination of data transfer combined with massive parallelism has the potential to provide a very high computational throughput that exceeds conventional CPUs and GPUs. However, to achieve this promising potential, we must overcome several challenges involving operation complexity, control flow divergence, area, power, reliability, and endurance. In this talk, I will first describe shortly the mMPU architecture and its potential. Then, I and will present the key challenges and how we address them, and as a result, which applications may benefit more from this kind of in-memory processing. |
Trevor Mudge (Univ. of Michigan)  |
New Applications Stress Memory Systems (slides, recording)  |
|---|
Details
Trevor Mudge received the Ph.D. in Computer Science from the University of Illinois, Urbana. He is the Bredt Family Professor of Computer Science and Engineering at the University of Michigan, Ann Arbor. He is author of numerous papers on computer architecture, programming languages, VLSI design, and computer vision. He has chaired 56 PhD theses in these areas. In 2014 he received the ACM/IEEE CS Eckert-Mauchly Award and the University of Illinois Distinguished Alumni Award. He is a Life Fellow of the IEEE, a Fellow of the ACM, and a member of the IET and the British Computer Society. |
Many important new applications have irregular memory accesses that cause added stress to memory systems. In this brief talk we will discuss this and suggest solutions. |
Avi Mendelson (Technion - Israel Institute of Technology)   |
Past → Present → Past (slides, recording)   |
|---|
Details
Avi Mendelson is an IEEE Fellow and a visiting professor at the Computer Science Department, Technion Israel. He has vast Academic and Industrial experience (Intel, Microsoft, National Semiconductors, and more). His main research interests are: computer architecture, low-power computers, hardware security, and accelerators for machine learning. |
In this talk, I will extend the discussion of how the field of computer architecture was changed over the last 2 decades. I will mainly focus on fundamental changes vs. adaptation to new technologies vs. the impact of the new application domains. |
10:30 - 11:00 Coffee break (Jardí)
11:00 - 12:30 Session 2 (Chairperson: Theo Ungerer - Uni. Augsburg)
Intervention by Daniel Crespo (Rector of UPC) (recording)
Guri Sohi (Univ. of Wisconsin-Madison)  |
We know how we got here. What does it tell us about where we go? (slides, recording)  |
|---|
Details
Guri Sohi has been a faculty member in the Computer Sciences Department at the University of Wisconsin-Madison since 1985 where he is currently a Vilas Research Professor. |
Out of order processors, which were criticized as esoteric and impractical for general-purpose processing, are now ubiquitous. They are found in low-power mobile devices as well as high-end servers in datacenters. Meanwhile new computing applications, notably machine learning, continue to demand more powerful and energy-efficient processing. What can we learn from the past for the future? |
Jaime Moreno (IBM T.J. Watson)  |
Calling for the return of non-virtualized microprocessors (slides, recording) |
|---|
Details
Jaime H. Moreno is Distinguished Researcher at the IBM Thomas J. Watson Research Center, where he currently focuses on security, isolation, and performance co-design for Cloud systems infrastructure. Previously, Jaime has been Senior Manager, and Technology and Operations Manager. Jaime joined IBM Research in 1992. He has multiple journals and conferences publications and is coauthor of the books "Introduction to Digital Systems" (Wiley, 1999) and "Matrix Computations on Systolic-Type Arrays" (Kluwer, 1992). Before joining IBM Research, Jaime was faculty member at the University of Concepcion, Chile. He received his Ph.D. and M.S. degrees in Computer Science from the University of California Los Angeles, and a degree in Electrical Engineering from the University of Concepcion, Chile. |
Sharing computing resources in a microprocessor among multiple tenants (users, tasks) through virtualization conflicts with the need to provide security, isolation, and performance stability to those tenants. The issue has become highly relevant in processors that have more compute resources than the typical needs of individual tenants. This presentation advocates a return to non-virtualized microprocessors, especially for commodity systems, because the need to share hardware resources has been overcome by the abundance of such resources in chips. However, there must exist mechanisms that enable composing sub-chip secure isolated server instances whose compute capabilities are driven by the tenants’ requirements, without relying on a hypervisor, opening the need for research and innovations in this area. |
Miquel Pericàs (Chalmers)  |
From Kilo-Instruction to Kilo-Chiplet Processors (slides, recording) 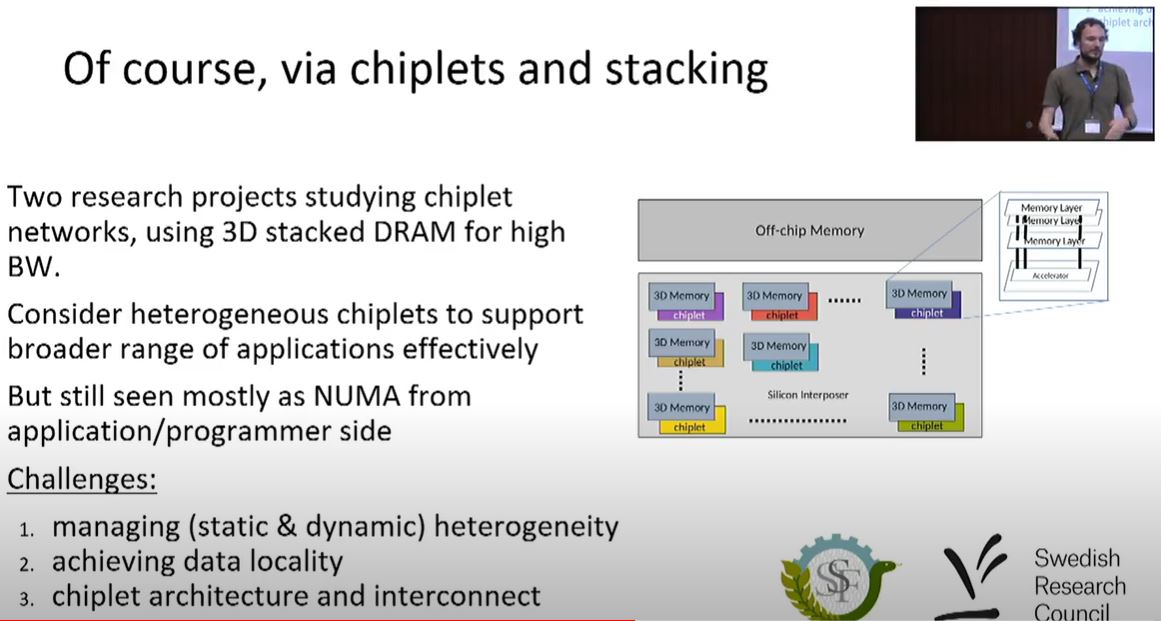 |
|---|
Details
Miquel Pericàs is an Associate Professor at the Department of Computer Science and Engineering at Chalmers University of Technology, where he has been since 2014. Miquel holds a Phd from Universitat Politècnica de Catalunya obtained in 2008. He was a senior researcher at BSC from 2008-2011, and a postdoctoral fellow at Tokyo Instituted of technology from 2012-2014. His main research interests lie in the areas of parallel and heterogeneous computing, ranging from autonomous systems to high performance computing infrastructure. |
As the end of Dennard scaling and power density issues motivated a move away from high-performance single-thread processors to multicore processors, the end of Moore’s law is motivating the design of processor systems composed of multiple of chiplets. Chiplet-based designs provide the flexibility to match both the architecture and technology to the purpose of each chip, but they introduce a new level of hierarchy along with higher inter-chiplet communication costs. In this talk I will present some of our views on how a large multi-chiplet processor can be built, and discuss approaches to dynamically manage its vast resources, with a focus on mapping applications to heterogeneous components. |
Carlos Álvarez (BSC and UPC)  |
Two nearly unrelated research topics: Approximate Computing & Hardware Task Scheduling (slides, recording) |
|---|
Details
Carlos Àlvarez received his M.S. and Ph.D. degrees in Computer Science from Universitat Politecnica de Catalunya (UPC), Spain, in 1998 and 2007, respectively. He is currently a tenured assistant professor in the department of Computer Architecture at UPC and an associated researcher at the BSC. His research interests include parallel architectures, runtime systems, and reconfigurable solutions for highperformance multiprocessor systems. He has participated on several EU projects related to the use of FPGAs for HPC like AXIOM, EuroEXA or LEGaTO. He is currently participating in the Textarossa and MEEP projects. He has coauthored more than 50 publications in international journals and conferences. He has co-advised four Ph.D. theses and he is currently co-advising three PhD students. |
In this talk I will present the basic ideas of two different research topics. The first part, approximate computing, presents some developments that were precursors of a widely developed research field that is still active. The second one, hardware task scheduling, advocates for increasing the hardware support to runtime features to tackle bottlenecks that arise in manycore systems when they try to synchronize different execution threads from single applications. Finally, I will explain how these two seemingly separate research topics are related and some insights that I have obtained from them. |
12:30 - 14:00 Lunch (Jardí)
14:00 - 16:00 Open Mic & Video session (Chairperson: Prof. Yale Patt)
Recordings congratulating Mateo sent by colleagues and friends:
-
Wen-mei Hwu (Univ. of Illinois at Urbana-Champaign), video
-
Alba Cristina Magalhaes Alves de Melo (Univ. of Brasilia), video
-
Marc Snir (Univ. of Illinois at Urbana-Champaign), video
-
Manolis Katevenis (Univ. of Crete and FORTH), video
-
Koen DeBosschere (Univ. of Gent), video
-
Marc Duranton (CEA), video
-
Carlos Jaime (Univ. of Bucaramanga, Colombia), video
-
Esteban Mocskos (Univ. de Buenos Aires), video
-
Isidoro Gitler (Instituto Politécnico Nacional de México), video
16:00 - 16:30 Coffee break (Jardí)
16:30 - 17:45 Session 3 (Chairperson: Alex Veidenbaum - UCI)
| Pradip Bose and Augusto Vega (IBM T.J. Watson) | Ushering in the Epoch of Domain-Specific Accelerators and SoCs: Challenges and Pitfalls (slides, recording) |
|---|
Details
Pradip Bose is a Distinguished Research Staff Member and manager of Efficient and Resilient Systems at IBM T. J. Watson Research Center. He has over thirty-nine years of experience at IBM, and was a member of the pioneering RISC super scalar project at IBM (a pre-cursor to the first RS/6000 system product). He holds a Ph.D. degree from University of Illinois at Urbana-Champaign. Pradip is a member of IBM’s Academy of Technology and is a Fellow of the IEEE. He is the lead Principal Investigator of the IBM-led EPOCHS project that forms the basis of the proposed presentation at this workshop. Augusto Vega is a Research Staff Member at IBM T. J. Watson Research Center involved in research and development work in the areas of highly reliable, power-efficient embedded designs, cognitive systems and mobile computing. He holds a Ph.D. degree from Universitat Politècnica de Catalunya (UPC), Spain. In the IBM-led EPOCHS project, Augusto is the designated Chief Technical Officer (CTO) of Technology Transition and he is also the technical lead of key software enablement tasks in the project. |
The age specialization in the late CMOS era is supposed to have ushered in a new epoch of domain-specific acceleration and heterogeneous compute nodes. Some have forecasted the emergence of a “sea of accelerators” paradigm for future processors. In this talk, we examine the current advances in multi-core heterogeneous systems-on-chip (SoCs) in the particular context of research that we have pursued at IBM in our EPOCHS1 project under the auspices of DARPA’s DSSoC2 program. In particular, we describe two aspects of the research challenge: (a) agile design methods to achieve drastic reduction in development cost, while achieving target metrics of energy efficiency; and (b) software programmability of heterogeneous SoCs. We point to potential commercialization opportunities of the EPOCHS methodology while also highlighting the pitfalls of pursuing the dual objectives referred to above. 1EPOCHS = Efficient Programmability of Cognitive Heterogeneous Systems; an IBM-led research project pursued in collaboration with Harvard University, Columbia University and University of Illinois at Urbana-Champaign. 2DSSoC = Domain-Specific System-on-Chip. |
| Alex Ramírez (Google) | Successful co-Design of a Planet-scale Hardware Acceleration Platform (slides, recording) |
|---|
Details
Bio |
The talk discusses the journey, from concept to planet-scale development, of the Video transCoding Unit (VCU) that Google developed to accelerate the video processing at YouTube. That said, the talk will not be just about the VCU: we will focus on the key lessons we learned through the process that will benefit future co-design projects. Some of the key elements that we will discuss include having an engaged customer from day 0, focusing on software readiness, checking the validity of your assumptions along the path, and never underestimating the impact of the things we did not plan ahead for. |
| Uri Weiser (Technion - Israel Institute of Technology) | Wake up call: Now is the perfect time for innovation (slides, recording) |
|---|
Details
Uri Weiser is a Professor emeritus at the Electrical and Computing Engineering (ECE) department, the Technion IIT and is involved with numerous startups. He received the bachelor and master degrees in ECE from the Technion and Ph.D in CS from the University of Utah, SLC. Professor Weiser worked at Intel from 1988 till 2007. At Intel, Weiser initiated the definition of the Pentium® processor, drove the definition of Intel’s MMX™ technology, invented the Trace Cache, co-managed the a new Intel Microprocessor Design Center at Austin, Texas and formed an Advanced Media applications research activity. Professor Weiser was appointed an Intel Fellow in 1996, in 2002 he became an IEEE Fellow and in 2005 an ACM Fellow. In 2016 Professor Weiser received the IEEE/ACM Eckert-Mauchly Award for “leadership, as well as pioneering industry and academic work in high performance processors and multimedia architectures”. The Eckert-Mauchly award is known as the computer architecture community’s most prestigious award. Prior to his career at Intel, Professor Weiser worked for the Israeli Department of Defense as a research and system engineer and later with National Semiconductor Design Center in Israel, where he led the design of the NS32532 microprocessor. Professor Weiser was an Associate Editor of IEEEMicro Magazine and was Associate Editor of Computer Architecture Letters. |
During the past 40 years, General Purpose Architecture Implementations led the industry, while new “killer applications” (e.g. MMX, Media) followed. Nowadays a vast amount of new Machine Learning applications are leading the need for new architectures. I’ll try to briefly describe this current trend that calls for a new era in which new architectures innovation will be a must. In this presentation I will also describe my fruitful interactions with Professor Valero Mateo and his gigantic leadership in our field. |
18:00 - 19:30 Session 4 (Chairperson: Alex Nicolau - UCI)
| John Davis (BSC) | The RISC-V Revolution at BSC (slides, recording) |
|---|
Details
John D. Davis is the Director of the Laboratory for Open Computer Architecture at Barcelona Supercomputing Center. He has published over 30-refereed conference and journal papers in Computer Architecture (ASIC and FPGA-based domain-specific accelerators, non-volatile memories, and processor design), Distributed Systems, and Bioinformatics. He also holds over 35 issued or pending patents in the USA and Europe. He has designed and built distributed storage systems in research and as products. John has led the entire product strategy, roadmap, and execution for a big data and analytics company. He has worked in research at Microsoft Research, where he also co-advised 4 PhDs, as well as large and small start-up companies. John holds a B.S. in Computer Science and Engineering from the University of Washington. He also holds an M.S. and Ph.D. in Electrical Engineering from Stanford University. At BSC, John is leading the MEEP project and is the technical leader of the eProcesor project and the European PILOT project. He also leads several industrial research collaborations, all centered around a full open source ecosystem from software down to hardware, open-source processors, and accelerators. John is the founder and chair of the RISC-V Special Interest Group on High-Performance Computing (SIG-HPC). |
The RISC-V ISA provides a common research language that can be used to demonstrate new ideas. It provides software compatibility and extenibility. At BSC, we use the RISC-V ISA to promote an HPC Open System Stack, enabling HW/SW co-design. Using the RISC-V ISA, we can produce CPU cores to accelerators, enabling high quality research based on building real HW and the associated software. This talk will highlight some of the projects that are creating foundational building blocks for the BSC RISC-V ecosystem, from cores to accelerators and tools to enable HW/SW codesign, and systems research. |
| Peter Hofstee (IBM Austin) | What I have learned about computer system memory, and what I am still figuring out (slides, recording) |
|---|
Details
H. Peter Hofstee is best known for his contributions to Heterogeneous computing as the chief architect of the Synergistic Processor Elements in the Cell Broadband Engine processor used in the Sony PlayStation 3 and the first supercomputer to reach sustained Petaflop operation. After returning to IBM research in 2011 he has focused on optimizing the system roadmap for big data, analytics, and cloud, including the use of accelerated compute. His early research work on coherently attached reconfigurable acceleration on POWER7 paved the way for the coherent attach processor interface (CAPI) on POWER8 and OpenCAPI on Power9 and Power10. Since 2000 Peter has joined the Power Systems Performance organization working on performance aspects of future processors and systems. |
This talk will cover a journey from sharing byte-addressable memory between heterogeneous processor elements to complete systems, the software models that go a long with these, and the efficiencies that can be gained. |
| Per Stenstrom (Chalmers/ZeroPoint Technologies) | Towards Data-Centric Architectures (slides, recording) |
|---|
Details
Per Stenstrom is professor at Chalmers University of Technology. His research interests are in parallel computer architecture. He has authored or co-authored four textbooks, about 200 publications and twenty patents in this area. He has been program chairman of several top-tier IEEE and ACM conferences including IEEE/ACM Symposium on Computer Architecture and acts as Associate Editor of ACM TACO, Topical Editor IEEE Transaction on Computers and Associate Editor-in-Chief of JPDC. He is a Fellow of the ACM and the IEEE and a member of Academia Europaea, the Royal Swedish Academy of Engineering Sciences and the Royal Spanish Academy of Engineering Science. |
As applications are becoming more data intensive, they become more and more incompatible with decades of focus on compute-centric architectures. This talk will focus on why a departure from compute-centric to data-centric architectures is warranted and propose some technical approaches to make it happen mid-term and long-term that we are investigating at Chalmers and at ZeroPoint Technologies. |
| Ramón Beivide (Univ. of Cantabria) | Funny Notes about a Friendship and some Interconnection Networks (slides, recording) |
|---|
Details
Ramon Beivide is a professor of Computer Architecture at the Universidad de Cantabria (UC, Spain) and the scientific director of its Supercomputing Services, whose node Altamira belongs to the RES (Spanish Supercomputing Network). He is also associated researcher at BSC. He obtained a PhD degree in Computer Science from UPC in 1985. Since 1991, he teaches computer architecture, high-performance computing and interconnection networks at the UC in the Telecommunication Engineering School and the Computer Science School of which was its first Director in 2004. Previously, he has been professor at UAB, UPC and UPV/EHU and visiting researcher at UCLA, UC Irvine, Adelaide University, IBM Zurich Labs and BSC/UPC. His main research interests include high-performance computing, networks on chip and system-level interconnection networks. He is the leader of the Computer Architecture and Technology research group at UC and has supervised or co-supervised 15 PhD theses on these topics. Some of the technical contributions presented on these theses are used by the industry, like the interconnection mechanisms employed by the IBM BlueGene supercomputers and other big machines from Russia and China. He has published more than 150 technical papers on these topics. |
Currently, computing facilities are moving massively to the cloud. Billions of mobile small computers, such as phones and tablets, are continuously accessing the millions of computing servers housed in huge Data Centers (DC) distributed around the world. Last year, the generated traffic exceeded 20 ZettaBytes, and it is expected to grow between 50% and 60% per year, mainly due to the pervasive use of Artificial Intelligence applications. Around 70% of this traffic is managed within the DCs themselves. To cope with such vast amounts of traffic efficiently, DCs rely on an interconnect hierarchy. This talk will present some proposals about the network architectures and technologies used to build such interconnect hierarchies in the most modern DCs and their possible evolution in the near future. In parallel, certain funny notes about research and project collaborations on networks between the speaker and Prof. Valero will be exposed. |
Friday, September 2nd, 2022
10:00 - 10:30 Coffee break (Jardí)
10:30 - 12:30 Session 5 (Chairperson: Lawrence Rauchwerger - UIUC)
| Miquel Moretó (BSC and UPC) | Lagarto: Fabricating the First RISC-V Processor at BSC (slides, recording) |
|---|
Details
Bio |
abstract |
| David Kaeli (Northeastern Univ.) | Adventure in Heterogeneous Computing (slides, recording) |
|---|
Details
David Kaeli received his PhD in Electrical Engineering from Rutgers University. He is a Distinguished Processor on the ECE faculty at Northeastern University, where he directs the NU Computer Architecture Research Laboratory (NUCAR). In addition to over 450 papers, he has published 3 textbooks focused on Heterogeneous Computing. Dr. Kaeli is a Fellow of both the ACM and IEEE. |
As graphics processors matured from serving as 3-D graphic rendering engines to today’s high performance accelerators, we have seen major advances in both architecture and programming support. This talk reflects on some of the key advances in this field, and suggests what the future will look like as we continue to see new types of accelerators and software stacks being delivered. |
| Jesús Labarta (BSC and UPC) | Poor man’s Rolls Royce. The Risc-V "accelerator" in EPI (slides, recording) |
|---|
Details
Prof. Jesús Labarta received his Ph.D. in Telecommunications Engineering from UPC in 1983, where he has been a full professor of Computer Architecture since 1990. He was Director of European Center of Parallelism at Barcelona from 1996 to the creation of BSC in 2005, where he is the Director of the Computer Sciences Dept. His research team has developed performance analysis and prediction tools and pioneering research on how to increase the intelligence embedded in these performance tools. He has also led the development of OmpSs and influenced the task based extension in the OpenMP standard. He has led the BSC cooperation with many IT companies. He is now responsible of the POP center of excellence providing performance assessments to parallel code developers throughout the EU and leads the RISC-V vector accelerator within the EPI project. He has pioneered the use of Artificial Intelligence in performance tools and will promote their use in POP, as well as the AI-centric co-designing of architectures and runtime systems. He was awarded the 2017 Ken Kennedy Award for his seminal contributions to programming models and performance analysis tools for high performance computing, being the First Non US Researcher receiving it. |
The European Processor Initiative (EPI) project aims at developing European processor technology for High Performance Computing (HPC) and emerging application areas. Trying to catch up worldwide leading actors and with a limited budget poses a real challenge. In this situation, acknowledging the constraints and properly combining components that individually may not be directly competitive, can result in very reasonable designs. A part of the EPI project has addressed this challenge to develop a fully owned implementation of accelerators based on RISC-V cores. The talk will present the EPI project, focus on the fundamental aspects of the vision behind the design and the overall resulting architecture and then report on the achievements and current status of the project around the RISC-V vector ISA. The project has produced a test chip in GF22nm technology, featuring 4 vector cores, 2 STX clusters and one VRP processor. In parallel, an FPGA implementation of the vector core and memory subsystem has been implemented to be used as a software development vehicle (SDV), CI and co-design support infrastructure. This system runs as stand alone self hosted Linux node where general purpose applications from the HPC but also other domains can be run. I will report some initial results of these evaluations and comparisons to otherstate of the art architectures. |
| Francisco Cazorla (BSC and Maspatechnologies) | Time-Predictable Fault Tolerant high-performance processors: lessons learned and future prospects (slides, recording) |
|---|
Details
Francisco J. Cazorla is the director of the Computer Architecture/Operating Systems research group at the BSC and co-founder of Maspatechnologies S.L (a BSC spin-off). Francisco has been working on hardware and software designs for embedded critical systems to improve non-functional metrics like software timing predictability and functional safety. Francisco has led 4 research projects with the European Space Agency and 3 European Projects on these topics (MASTECS, PROXIMA, PROARTIS). He is also a grant holder of the European Research Council (ERC). |
We are witnessing increasing demands for time predictability and functional safety across different computing domains including high-performance (datacenter and supercomputers), handheld, and embedded devices. This trend is driven by the use of computers to control a growing number of critical aspects of our life, including health, security and safety, in professional and personal activities. High-performance is usually achieved by deploying aggressive hardware features (e.g. multi-level caches, heterogeneous designs) that negatively impact non-functional metrics like time predictability and functional safety. The challenge lies on finding hardware/software designs that balance high-performance and non-functional metrics. In this talk I will focus on the increasing needs of time predictability and safety in computing systems. I will present some of the main challenges in the design of multicores and manycores to provide increasing degrees of time predictability and safety without significantly degrading average performance. |
| Onur Mutlu (ETH Zurich) | Memory Centric Computing (slides, recording) |
|---|
Details
Onur Mutlu is a Professor of Computer Science at ETH Zurich. He is also a faculty member at Carnegie Mellon University, where he previously held the Strecker Early Career Professorship. His current broader research interests are in computer architecture, systems, hardware security, and bioinformatics. A variety of techniques he, along with his group and collaborators, has invented over the years have influenced industry and have been employed in commercial microprocessors and memory/storage systems. He obtained his PhD and MS in ECE from the University of Texas at Austin and BS degrees in Computer Engineering and Psychology from the University of Michigan, Ann Arbor. He started the Computer Architecture Group at Microsoft Research (2006-2009), and held various product and research positions at Intel Corporation, Advanced Micro Devices, VMware, and Google. He received the Intel Outstanding Researcher Award, IEEE High Performance Computer Architecture Test of Time Award, NVMW Persistent Impact Prize, the IEEE Computer Society Edward J. McCluskey Technical Achievement Award, ACM SIGARCH Maurice Wilkes Award, the inaugural IEEE Computer Society Young Computer Architect Award, the inaugural Intel Early Career Faculty Award, US National Science Foundation CAREER Award, Carnegie Mellon University Ladd Research Award, faculty partnership awards from various companies, and a healthy number of best paper or "Top Pick" paper recognitions at various computer systems, architecture, and security venues. He is an ACM Fellow "for contributions to computer architecture research, especially in memory systems", IEEE Fellow for "contributions to computer architecture research and practice", and an elected member of the Academy of Europe (Academia Europaea). His computer architecture and digital logic design course lectures and materials are freely available on YouTube (https://www.youtube.com/OnurMutluLectures), and his research group makes a wide variety of software and hardware artifacts freely available online (https://safari.ethz.ch/). For more information, please see his webpage at https://people.inf.ethz.ch/omutlu/. |
Computing is bottlenecked by data. Large amounts of application data overwhelm s torage capability, communication capability, and computation capability of the modern machines we design today. As a result, many key applications' performance, efficiency, and scalability are bottlenecked by data movement. In this lecture, we describe three major shortcomings of modern architectures in terms of 1) dealing with data, 2) taking advantage of the vast amounts of data, and 3) exploiting different semantic properties of application data. We argue that an intelligent architecture should be designed to handle data well. We show that handling data well requires designing architectures based on three key principles: 1) data-centric, 2) data-driven, 3) data-aware. We give several examples for how to exploit each of these principles to design a much more efficient and high performance computing system. We especially discuss recent research that aims to fundamentally reduce memory latency and energy, and practically enable computation close to data, with at least two promising novels directions: 1) processing using memory, which exploits analog operational properties of memory chips to perform massively-parallel operations in memory, with low-cost changes, 2) processing near memory, which integrates sophisticated additional processing capability in memory controllers, the logic layer of 3D-stacked memory technologies, or memory chips to enable high memory bandwidth and low memory latency to near-memory logic. We show both types of architectures can enable orders of magnitude improvements in performance and energy consumption of many important workloads, such as graph analytics, database systems, machine learning, video processing. We discuss how to enable adoption of such fundamentally more intelligent architectures, which we believe are key to efficiency, performance, and sustainability. We conclude with some guiding principles for future computing architecture and system designs. An overview & survey of modern memory-centric computing can be found here and also serves as recommended reading: "A Modern Primer on Processing in Memory" |
Mateo 2022 and ACM Summer School 2022 join efforts for lunch and the rest of the day
12:30 - 13:30 Lunch (Jardí)
13:30 - 14:30 Industrial view of the Future of HPC
Shared session with questions for Min Li (Huawei) and Jordi Caubet (IBM) (recording)
14:30 - 15:00 EuroHPC talk, Josephine Wood (EuroHPC), "Towards a European HPC ecosystem" (slides, recording)
15:00 - 16:30 Panel: The Future of HPC (recording)
Moderator: Josephine Wood (EuroHPC)
Panelists: Paul Messina (ANL), Uri Weiser (Technion), Per Stenstrom (Chalmers), Min Li (Huawei), Alba Cervera (BSC)
16:30 - 17:00 Coffee break (Jardí)
17:00 - 18:30 Closing lecture by Mateo Valero (BSC Director) (slides, recording)
Student Diploma Ceremony
18:30 - 20:30 Farewell Party (Jardí)
20:30 Adjourn
Mateo Valero biography
You can find the biography and curriculum vitae of Mateo Valero, on the BSC website (https://www.bsc.es/mateo-valero).
Organizers
The organization of MATEO2022 is shared between Universitat Politècnica de Catalunya and the Barcelona Supercomputing Center. Thanks for your support!

